Data Analytics
Data Analytics
Data Analytics
Data Mining

Data mining involves six common classes of tasks:
Anomaly detection (Outlier/change/deviation detection) - The identification of unusual data records, that might be interesting or data errors that require further investigation.
Association rule learning (Dependency modelling) - Searches for relationships between variables. For example, a supermarket might gather data on customer purchasing habits. Using association rule learning, the supermarket can determine which products are frequently bought together and use this information for marketing purposes. This is sometimes referred to as market basket analysis.
Clustering - is the task of discovering groups and structures in the data that are in some way or another "similar", without using known structures in the data.
Classification - is the task of generalizing known structure to apply to new data. For example, an e-mail program might attempt to classify an e-mail as "legitimate" or as "spam".
Regression - attempts to find a function which models the data with the least error.
Summarization - providing a more compact representation of the data set, including visualization and report generation.
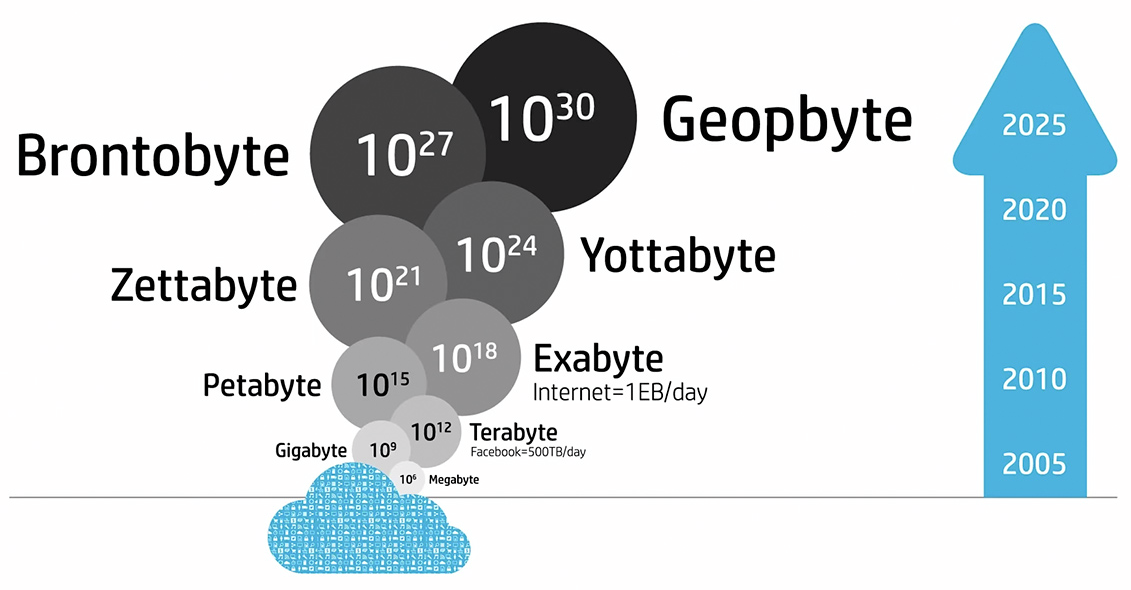
Big Data
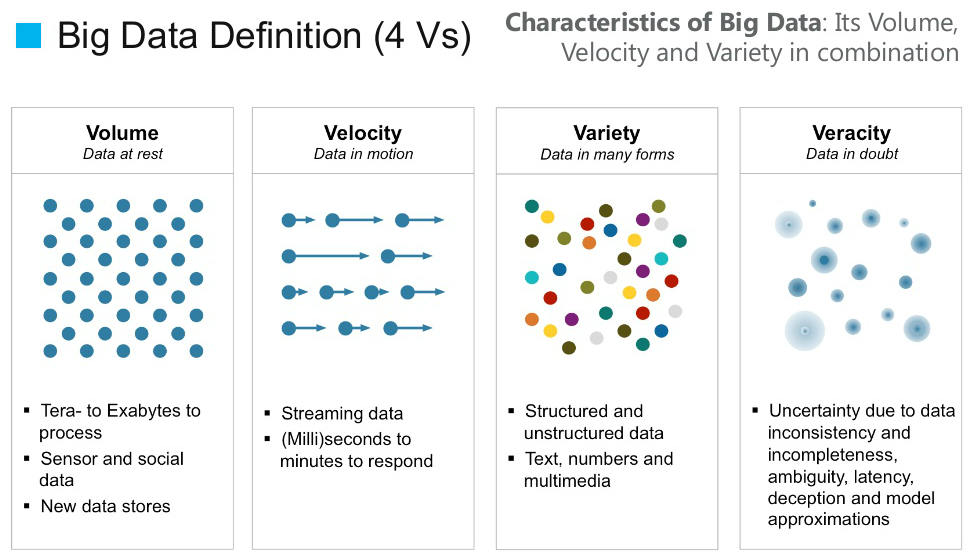
Big data is a term for data sets that are so large or complex that traditional data processing application softwares are inadequate to deal with them. The term "Big Data" often refers simply to the use of predictive analytics, user behavior analytics, or certain other advanced data analytics methods that extract value from data. Big data analytics applies data mining, predictive analytics and machine learning tools to sets of big data that often contain unstructured and semi-structured data. Text mining provides a means of analyzing documents, emails and other text-based content.Big Data 4Vs Definition
Big Data - Trends and Forecasts